使用Python抓取欧洲足球联赛数据进行大数据分析
背景
Web Scraping
在大数据时代,一切都要用数据来说话,大数据处理的过程一般需要经过以下的几个步骤
-
数据的采集和获取
-
数据的清洗,抽取,变形和装载
-
数据的分析,探索和预测
-
数据的展现
其中首先要做的就是获取数据,并提炼出有效地数据,为下一步的分析做好准备。
数据的来源多种多样,以为我本身是足球爱好者,而世界杯就要来了,所以我就想提取欧洲联赛的数据来做一个分析。许多的网站都提供了详细的足球数据,例如:
这些网站都提供了详细的足球数据,然而为了进一步的分析,我们希望数据以格式化的形式存储,那么如何把这些网站提供的网页数据转换成格式化的数据呢?这就要用到Web scraping的技术了。简单地说,Web Scraping就是从网站抽取信息, 通常利用程序来模拟人浏览网页的过程,发送http请求,从http响应中获得结果。
Web Scraping 注意事项
在抓取数据之前,要注意以下几点:
-
阅读网站有关数据的条款和约束条件,搞清楚数据的拥有权和使用限制
-
友好而礼貌,使用计算机发送请求的速度飞人类阅读可比,不要发送非常密集的大量请求以免造成服务器压力过大
-
因为网站经常会调整网页的结构,所以你之前写的Scraping代码,并不总是能够工作,可能需要经常调整
-
因为从网站抓取的数据可能存在不一致的情况,所以很有可能需要手工调整
Python Web Scraping 相关的库
Python提供了很便利的Web Scraping基础,有很多支持的库。这里列出一小部分
-
BeautifulSoup http://www.crummy.com/software/BeautifulSoup/
-
Scrapy http://scrapy.org/
-
webscraping https://code.google.com/p/webscraping/
当然也不一定要用Python或者不一定要自己写代码,推荐关注import.io
Web Scraping 代码
下面,我们就一步步地用Python,从腾讯体育来抓取欧洲联赛13/14赛季的数据。
首先要安装Beautifulsoup
pip install beautifulsoup4
我们先从球员的数据开始抓取。
球员数据的Web请求是http://soccerdata.sports.qq.com/playerSearch.aspx?lega=epl&pn=2 ,返回的内容如下图所示:

该web服务有两个参数,lega表示是哪一个联赛,pn表示的是分页的页数。
首先我们先做一些初始化的准备工作
from urllib2 import urlopen import urlparse import bs4 BASE_URL = "http://soccerdata.sports.qq.com" PLAYER_LIST_QUERY = "/playerSearch.aspx?lega=%s&pn=%d" league = ['epl','seri','bund','liga','fran','scot','holl','belg'] page_number_limit = 100 player_fields = ['league_cn','img','name_cn','name','team','age','position_cn','nation','birth','query','id','teamid','league']
urlopen,urlparse,bs4是我们将要使用的Python库。
BASE_URL,PLAYER_LIST_QUERY,league,page_number_limit和player_fields是我们会用到的一些常量。
下面是抓取球员数据的具体代码:
def get_players(baseurl):
html = urlopen(baseurl).read()
soup = bs4.BeautifulSoup(html, "lxml")
players = [ dd for dd in soup.select('.searchResult tr') if dd.contents[1].name != 'th']
result = []
for player in players:
record = []
link = ''
query = []
for item in player.contents:
if type(item) is bs4.element.Tag:
if not item.string and item.img:
record.append(item.img['src'])
else :
record.append(item.string and item.string.strip() or 'na')
try:
o = urlparse.urlparse(item.a['href']).query
if len(link) == 0:
link = o
query = dict([(k,v[0]) for k,v in urlparse.parse_qs(o).items()])
except:
pass
if len(record) != 10:
for i in range(0, 10 - len(record)):
record.append('na')
record.append(unicode(link,'utf-8'))
record.append(unicode(query["id"],'utf-8'))
record.append(unicode(query["teamid"],'utf-8'))
record.append(unicode(query["lega"],'utf-8'))
result.append(record)
return result
result = []
for url in [ BASE_URL + PLAYER_LIST_QUERY % (l,n) for l in league for n in range(page_number_limit) ]:
result = result + get_players(url)
我们来看看抓取球员数据的详细过程:
首先我们定义了一个get_players方法,该方法会返回某一请求页面上所有球员的数据。为了得到所有的数据,我们通过一个for循环,因为要循环各个联赛,每个联赛又有多个分页,一般情况下是需要一个双重循环的:
for i in league:
for j in range(0, 100):
url = BASE_URL + PLAYER_LIST_QUERY % (l,n)
## send request to url and do scraping
Python的list comprehension可以很方便的通过构造一个列表的方式来减少循环的层次。
另外Python还有一个很方便的语法来合并连个列表: list = list1 + list2
好我们再看看如何使用BeautifulSoup来抓取网页中我们需要的内容。
首先调用urlopen读取对应url的内容,通常是一个html,用该html构造一个beautifulsoup对象。
beautifulsoup对象支持很多查找功能,也支持类似css的selector。通常如果有一个DOM对象是<xx class='cc'>,我们使用以下方式来查找:
obj = soup.find("xx","cc")
另外一种常见的方式就是通过CSS的selector方式,在上述代码中,我们选择class=searchResult元素里面,所有的tr元素,过滤掉th也就是表头元素。
for dd in soup.select('.searchResult tr') if dd.contents[1].name != 'th'
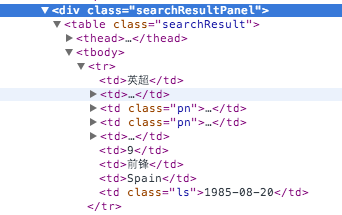
对于每一行记录tr,生成一条球员记录,并存放在一个列表中。所以我们就循环tr的内容tr.contents,获得对应的field内容。
对于每一个tr的content,我们先检查其类型是不是一个Tag,对于Tag类型有几种情况,一种是包含img的情况,我们需要取出球员的头像图片的网址。

另一种是包含了一个链接,指向其他数据内容

所以在代码中要分别处理这些不同的情况。
对于一个Tag对象,Tag.x可以获得他的子对象,Tag['x']可以获得Tag的attribute的值。
所以用item.img['src']可以获得item的子元素img的src属性。
对已包含链接的情况,我们通过urlparse来获取查询url中的参数。这里我们利用了dict comprehension的把查询参数放入一个dict中,最有添加到列表中。
dict([(k,v[0]) for k,v in urlparse.parse_qs(o).items()])
对于其它情况,我们使用Python 的and or表达式以确保当Tag的内容为空时,我们写入‘na’,该表达式类似C/C++或Java中的三元操作符 X ? A : B
然后有一段代码判断当前记录的长度是否大于10,不大于10则用空值填充,目的是避免一些不一致的地方。
if len(record) != 10:
for i in range(0, 10 - len(record)):
record.append('na')
最后,我们把query中的一些相关的参数如球员的id,球队的id,所在的联赛代码等加入到列表。
record.append(unicode(link,'utf-8')) record.append(unicode(query["id"],'utf-8')) record.append(unicode(query["teamid"],'utf-8')) record.append(unicode(query["lega"],'utf-8'))
最后我们把本页面所有球员的列表放入一个列表返回。
好了,现在我们拥有了一个包含所有球员的信息的列表,我们需要把它存下来,以进一步的处理,分析。通常,csv格式是一个常见的选择。
import csv
def write_csv(filename, content, header = None):
file = open(filename, "wb")
file.write('\xEF\xBB\xBF')
writer = csv.writer(file, delimiter=',')
if header:
writer.writerow(header)
for row in content:
encoderow = [dd.encode('utf8') for dd in row]
writer.writerow(encoderow)
write_csv('players.csv',result,player_fields)
这里需要注意的就是关于encode的问题。因为我们使用的时utf-8的编码方式,在csv的文件头,需要写入\xEF\xBB\xBF,详见这篇文章
好了现在大功告成,抓取的csv如下图:

因为之前我们还抓取了球员本赛季的比赛详情,所以我们可以进一步的抓取所有球员每一场比赛的记录

抓取的代码如下
def get_player_match(url):
html = urlopen(url).read()
soup = bs4.BeautifulSoup(html, "lxml")
matches = [ dd for dd in soup.select('.shtdm tr') if dd.contents[1].name != 'th']
records = []
for item in [ dd for dd in matches if len(dd.contents) > 11]: ## filter out the personal part
record = []
for match in [ dd for dd in item.contents if type(dd) is bs4.element.Tag]:
if match.string:
record.append(match.string)
else:
for d in [ dd for dd in match.contents if type(dd) is bs4.element.Tag]:
query = dict([(k,v[0]) for k,v in urlparse.parse_qs(d['href']).items()])
record.append('teamid' in query and query['teamid'] or query['id'])
record.append(d.string and d.string or 'na')
records.append(record)
return records[1:] ##remove the first record as the header
def get_players_match(playerlist, baseurl = BASE_URL + '/player.aspx?'):
result = []
for item in playerlist:
url = baseurl + item[10]
print url
result = result + get_player_match(url)
return result
match_fields = ['date_cn','homeid','homename_cn','matchid','score','awayid','awayname_cn','league_cn','firstteam','playtime','goal','assist','shoot','run','corner','offside','foul','violation','yellowcard','redcard','save']
write_csv('m.csv',get_players_match(result),match_fields)
抓取的过程和之前类似。
下一步做什么
现在我们拥有了详细的欧洲联赛的数据,那么下一步要怎么做呢,我推荐大家把数据导入BI工具来做进一步的分析。有两个比较好的选择:
Tableau在数据可视化领域可谓无出其右,Tableau Public完全免费,用数据可视化来驱动数据的探索和分析,拥有非常好的用户体验
Splunk提供一个大数据的平台,主要面向机器数据。支持每天免费导入500M的数据,如果是个人学习,应该足够了。
当然你也可以用Excel。 另外大家如果有什么好的免费的数据分析的平台,欢迎交流。
2022年9月02日 23:06
Haryana Board Model Paper 2023 Class 4 Pdf Download with Answers for English Medium, Hindi Medium, Urdu Medium & Students for Small Answers, Long Answer, Very Long Answer Questions, and Essay Type Questions to Term1 & Term2 Exams at official website. Haryana Board 4th Class Model Paper New Exam Scheme or Question Pattern for Sammittive Assignment Exams (SA1 & SA2): Very Long Answer (VLA), Long Answer (LA), Small Answer (SA), Very Small Answer (VSA), Single Answer, Multiple Choice and etc.